
Levi Burner
Postdoctoral Associate
Intelligent Sensing Lab
Perception and Robotics Group
Maryland Robotics Center Fellow
Department of Computer Science
University of Maryland
Imagine sitting at your desk, looking at objects on it. You do not know their exact distances from your eye in meters, but you can immediately reach out and touch them. Instead of an externally defined unit, your sense of distance is tied to your action's embodiment. In contrast, robots are assumed to be calibrated. To solve this, my work tackles Embodied Representation.
I am a Maryland Robotics Center Postdoctoral Fellow where I work with the Intelligence Sensing Lab and Perception and Robotics Group and am advised by Chris Metzler and Yiannis Aloimonos.
My thesis was awarded the Ann G. Wylie Dissertation Fellowship (2024). My work was awarded the Maryland Robotics Center Graduate Research Assistantship (2023), Google Open Source Peer Bonus for contributions to MuJoCo (2023), Future Faculty Fellowship (2023), Computation and Mathematics for Biological Networks Fellowship (2020), University of Maryland's Dean Fellowship (2019). My teaching won my department's Outstanding Teaching Assistant Award.
Publications
2025
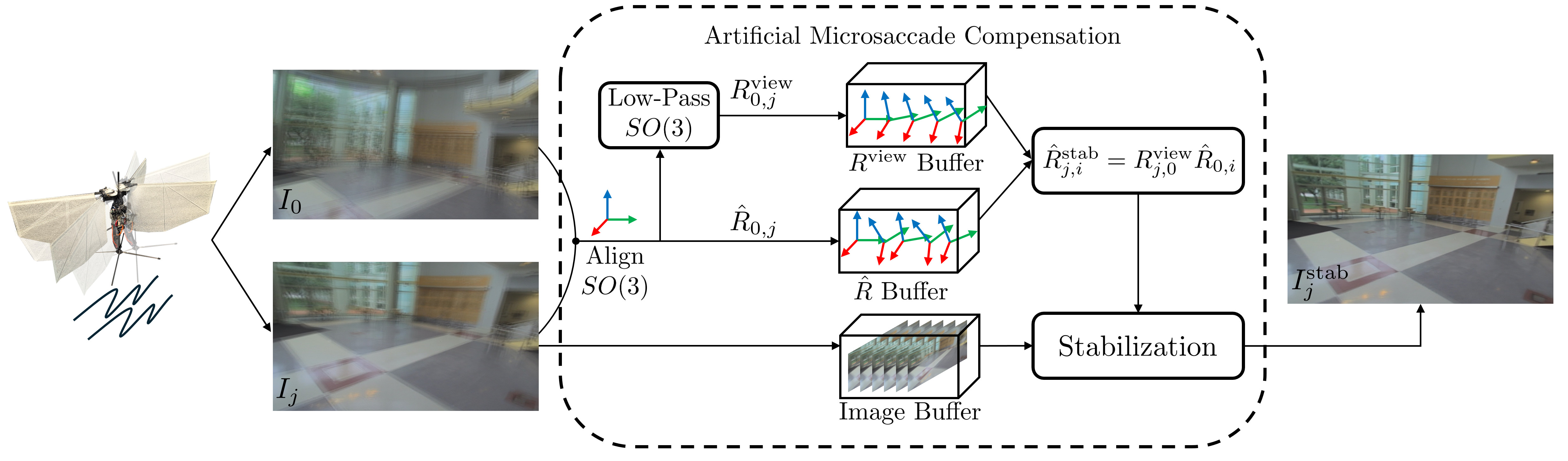
Artifical Microsaccade Stabilization:
Stable Vision for an Ornithopter
Levi Burner, Guido C.H.E. de Croon, Yiannis Aloimonos
Animals with foveated vision, experience microsaccades, small, rapid eye movements that they are not aware of. Inspired by this phenomenon, we develop a method for "Artificial Microsaccade Compensation". It can stabilize video captured by a tailless ornithopter that has resisted attempts to use camera-based sensing because it shakes at 12-20 Hz. Our approach minimizes changes in image intensity by optimizing over 3D rotation represented in SO(3). This results in a stabilized video, computed in real time, suitable for human viewing, and free from distortion.
Video - arXiv - CodeEmbodied Visuomotor Representation
Levi Burner, Cornelia Fermüller, Yiannis Aloimonos
We introduce Embodied Visuomotor Representation, a methodology for inferring distance in a unit implied by action. With it a robot without knowledge of its size, environmental scale, or strength can quickly learn to touch and clear obstacles within seconds of operation. Likewise, in simulation, an agent without knowledge of its mass or strength can successfully jump across a gap of unknown size after a few test oscillations.
Video - Nature Robotics (npj Robot) - Code
Learning Normal Flow Directly From Events
Dehao Yuan, Levi Burner, Jiayi Wu, Minghui Liu, Jingxi Chen, Yiannis Aloimonos, Cornelia Fermüller
Normal flow estimators are predominantly model-based and suffer from high errors. Using a local point cloud encoder, our method directly estimates per-event normal flow from raw events, producing temporally and spatially sharp predictions. Extensive experiments demonstrate our method achieves better and more consistent performance than state-of-the-art methods when transferred across different datasets.
ICCV 2025 - Code
Odometry Without Correspondence
from Inertially Constrained Ruled Surfaces
Chenqi Zhu, Levi Burner, Yiannis Aloimonos
Correspondence between two consecutive frames can be costly to compute and suffers from varying accuracy. If a camera observes a straight line as it moves, the image of the line sweeps a smooth surface in image-space time. Analyzing its shape gives information about odometry. Further, its estimation requires only differentially computed updates from point-to-line associations. By constraining the surfaces with the inertia measurements from an onboard IMU sensor, the dimensionality of the solution space is greatly reduced.
arXiv2024

Repurposing Pre-trained Video Diffusion Models for Event-based Video Interpolation
Jingxi Chen, Brandon Y. Feng, Haoming Cai, Tianfu Wang, Levi Burner, Dehao Yuan, Cornelia Fermuller, Christopher A. Metzler, Yiannis Aloimonos
Correspondence between two consecutive frames can be costly to compute and suffers from varying accuracy. If a camera observes a straight line as it moves, the image of the line sweeps a smooth surface in image-space time. Analyzing its shape gives information about odometry. Further, its estimation requires only differentially computed updates from point-to-line associations. By constraining the surfaces with the inertia measurements from an onboard IMU sensor, the dimensionality of the solution space is greatly reduced.
Video - CVPR 2025
Extremum Seeking Controlled Wiggling for Tactile Insertion
Levi Burner, Pavan Mantripragada, Gabriele M. Caddeo, Lorenzo Natale, Cornelia Fermüller, Yiannis Aloimonos
Correspondence between two consecutive frames can be costly to compute and suffers from varying accuracy. If a camera observes a straight line as it moves, the image of the line sweeps a smooth surface in image-space time. Analyzing its shape gives information about odometry. Further, its estimation requires only differentially computed updates from point-to-line associations. By constraining the surfaces with the inertia measurements from an onboard IMU sensor, the dimensionality of the solution space is greatly reduced.
Video - arXiv2023
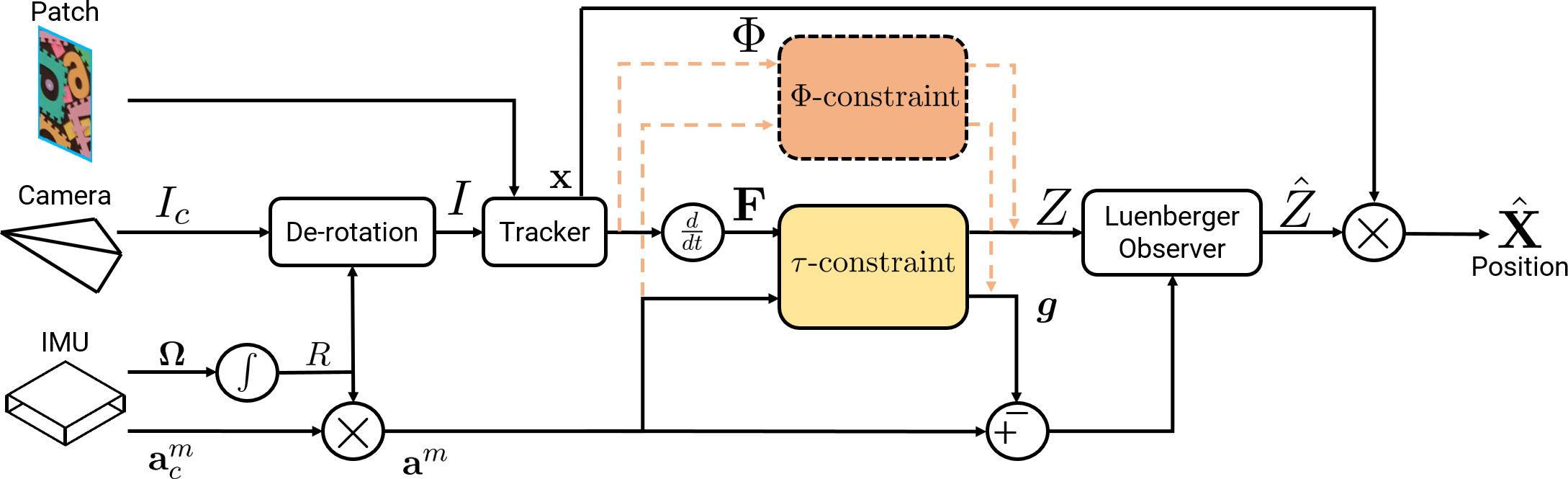
TTCDist: Fast Distance Estimation From an Active Monocular Camera Using Time-to-Contact
Levi Burner, Nitin J. Sanket, Cornelia Fermüller, Yiannis Aloimonos
Distance estimation from vision is fundamental for a myriad of robotic applications such as navigation, manipulation, and planning. Inspired by the mammal's visual system, which gazes at specific objects, we develop two novel constraints relating time-to-contact, acceleration, and distance that we call the -constraint and -constraint. They allow an active (moving) camera to estimate depth efficiently and accurately while using only a small portion of the image. The constraints are applicable to range sensing, sensor fusion, and visual servoing.
Video - ICRA 2023
EVIMO2: An Event Camera Dataset for Motion Segmentation, Optical Flow, Structure from Motion, and Visual Inertial Odometry in Indoor Scenes with Monocular or Stereo Algorithms
Levi Burner, Anton Mitrokhin, Cornelia Fermüller, Yiannis Aloimonos
A new event camera dataset, EVIMO2, is introduced that improves on the popular EVIMO dataset by providing more data, from better cameras, in more complex scenarios. As with its predecessor, EVIMO2 provides labels in the form of per-pixel ground truth depth and segmentation as well as camera and object poses. All sequences use data from physical cameras and many sequences feature multiple independently moving objects. Typically, such labeled data is unavailable in physical event camera datasets.
Website - arXiv (40 citations)